Big (and little) data is overwhelming us: securely archiving and managing that data is critical to its beneficial use
What is a Data Lake?
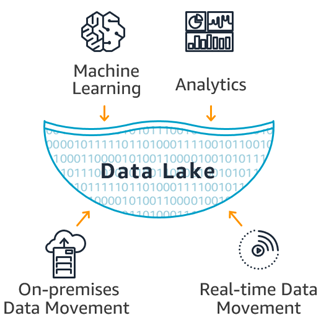
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data, and run different types of analytics—from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions.
The value in a data lake
Data lakes meet the need to harness and derive value from exploding data volumes. Raw data from new and diverse sources – web, mobile, connected devices, etc. – was often discarded in the past, but these sources contain invaluable insights. Massive volume inputs, plus new forms of analytics, demand a new way to manage and derive value from organizational data.
Humanitarian organizations like the UN Office for the Coordination of Humanitarian Affairs (OCHA) traffic immense data points that need to be properly secured, managed, and eventually organized for use.
OCHA, as an emergency response organization, recognizes that data is an important organizational asset requiring management and investment. We have been working to define process, standards, governance and technical solutions to provide data in a more predictable format to our users.
Suzanne Connolly, Chief, Information Services Section, OCHA
OCHA’s data lake, its raw data repository, will be used across 30 country offices in the five regions where OCHA coordinates humanitarian financing, policy, advocacy, and information management, including their 19 Humanitarian Adviser Teams.
With its partners, OCHA contributes to principled and effective humanitarian response through coordination, advocacy, policy, information management and humanitarian financing tools and services. OCHA’s country and regional offices are responsible for delivering the core functions in the field by leveraging functional expertise throughout the organization.
Data Lake versus Data Warehouse?
Data lakes and data warehouses are widely used for storing big data, but they are not the same.
A data lake is a pool of raw data for structured and unstructured data, for purposes to yet define.
A data warehouse is a repository for structured, filtered data that is defined and has already been processed for a specific purpose.
What Lies Beneath
UNICC has implemented a data lake for the UN Office for the Coordination of Humanitarian Affairs (OCHA). UNICC’s team, including Shashank Rai, CTO; Akilesh Nirapure, Cloud Architect; Enrique Puig, Database Systems Administrator; Elena Tejadillos, Business Intelligence Report Developer Technician and Domingo Gavila, Applications Developer worked with Suzanne Connolly, Chief of Information Services Section at OCHA to successfully coordinate the piloting of data lake operations.
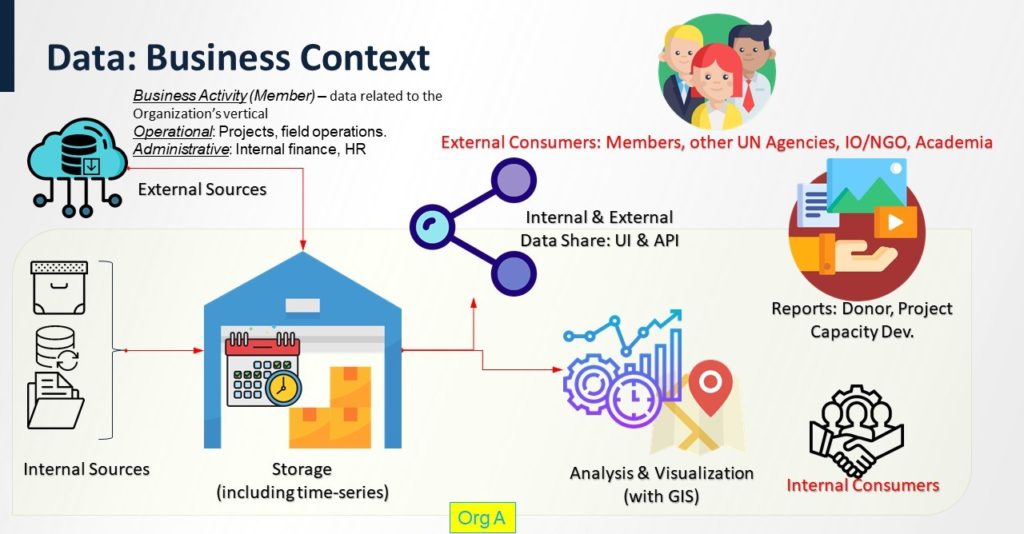
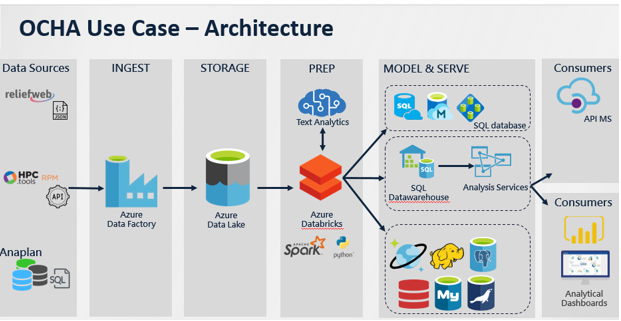
UNICC designed a data lake architecture founded in Microsoft Azure and based on best practices to allow for data source ingestion, storage, analytics, security, data modelling and serving to data warehouses and then to consumers through application APIs and dashboards.
The data lake secures humanitarian data of all sorts from files, objects and blobs (binary large objects – collections of binary data stored as single entities in database management systems), data interrogation and discovery, easy access to all data, and insights on the impact of humanitarian data.
The OCHA data lake leverages technologies that multiple downstream facilities can draw from, including data marts, data warehouses, and search engines. It will meet the need to derive value from massive data volumes plus new forms of analytics, requiring a new method to manage and derive value from data.
The data lake will provide and manage vast and growing sources of diverse data to help OCHA drive insight and inspiration in the delivery of its core mission of effective humanitarian response.
Shashank Rai, Chief Technology Officer, UNICC
Some of the benefits of data lakes include:
- Ability to store all types of structured, semi-structured, and unstructured data, from CRM data to social media posts
- Ability to store unlimited types of data, and derive value from that data
- More efficient access to data utilizing a single, more unified view of data across an organization
- Better data interrogation and discovery.
There are some challenges with implementing a data lake, which include:
- Multiple data sources concurrently publishing data
- Duplicity of data
- Inconsistent and complex Application Programming Interface (API) and User Interface (UI)
- Data governance and data security, i.e., confidentiality, integrity, and availability.
Shashank Rai, CTO at UNICC, presented the OCHA Data Lake success case at the UN Tech Huddle at Microsoft Geneva on October 2019. See details at the UNICC website.
OCHA, with its data lake now in place, can begin to utilize its raw data in the form of files, objects and blobs to provide greater value and insight to the organizations as the lake fills up, with clouds overhead, and provides for the OCHA humanitarian landscape.